GPU-infrastructuur: van capaciteitsprobleem naar kenniskloof
Recent onderzoek binnen de Kubernetes-community brengt een cruciale uitdaging aan het licht: organisaties worstelen niet met GPU-technologie op zich, maar met het effectief inzetten ervan. Het probleem is niet de beschikbaarheid—het probleem is de expertise.
De werkelijkheid achter de cijfers
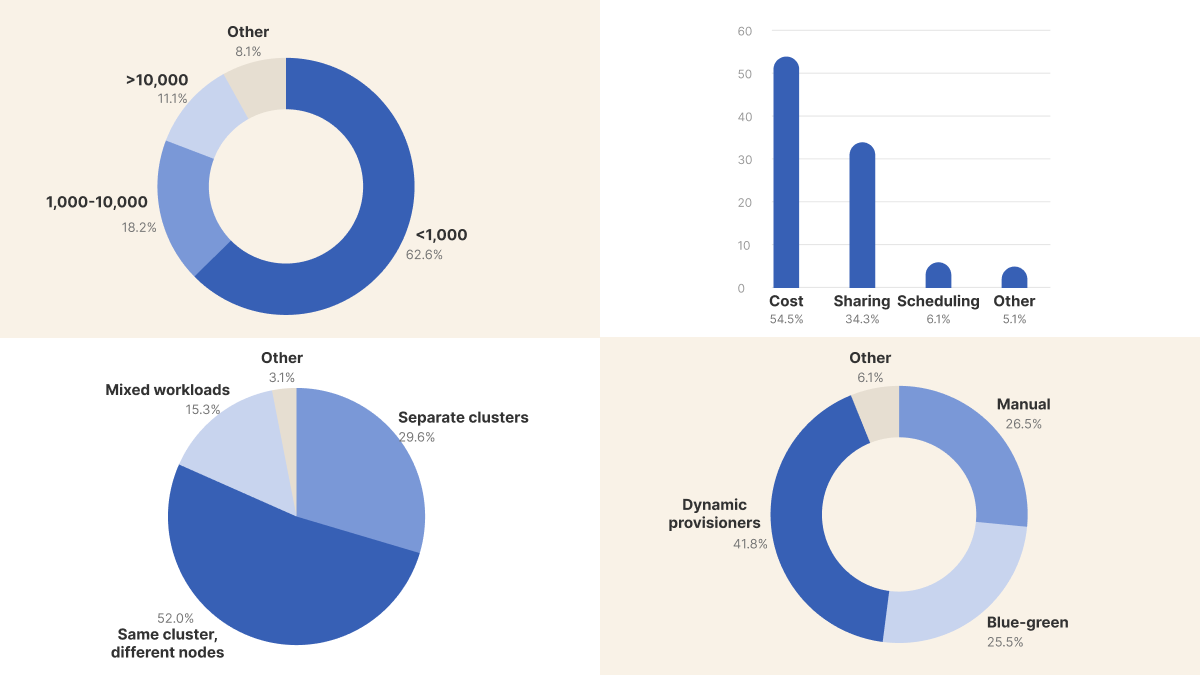
Cloud providers tonen indrukwekkende schaalmogelijkheden: clusters tot 100.000 nodes, OpenAI met meer dan 10.000 nodes. Onderzoek door Kube Today uit oktober 2025 onder 917 Kubernetes-professionals laat echter een andere werkelijkheid zien.
88% van de organisaties werkt met minder dan 10.000 nodes. De meerderheid blijft zelfs ruim onder de 1.000 nodes. Clusters onder de 100 nodes zijn eerder regel dan uitzondering.
Op zich is dit geen probleem. Het probleem ontstaat wanneer je architectuurbeslissingen baseert op theoretische maxima in plaats van praktische behoeften.
De echte kostenpost: inefficiëntie
Kostoptimalisatie komt in het onderzoek als grootste uitdaging naar voren. Maar dit is eigenlijk een gemaskeerd efficiëntieprobleem.
Een NVIDIA H100 instance kost ongeveer $10 per uur bij de grote cloud providers. Klinkt beheersbaar? Doe de rekensom:
Bij 20% benutting blijft 80% van de capaciteit onbenut. Dat is $70.080 aan gemiste waardecreatie per jaar, per GPU.
Het onderzoek toont een pijnlijke werkelijkheid. Enkele citaten van respondenten:
- "De uitdaging is dat developers ze niet goed kunnen gebruiken"
- "Nog nooit de kans gehad om ze te gebruiken"
Dit zijn geen uitzonderingen. Dit is een patroon. De bottleneck is verschoven van infrastructuurbeschikbaarheid naar organisatorische capaciteit.
De complexiteit achter GPU-orkestratie
Organisaties investeren in geavanceerde GPU-infrastructuur maar missen de kennis om deze effectief in te zetten. De uitdaging zit in concrete vraagstukken:
Orkestratie en workload management
- Hoe orkestreer je GPU-workloads effectief binnen Kubernetes?
- Wanneer kies je voor unified clusters versus gescheiden training en inference workloads?
- Hoe implementeer je node lifecycle management zonder downtime?
Resource management en multi-tenancy
- Welke resource quotas en affinities configureer je voor multi-tenancy?
- Hoe pak je zombie processes aan die blijven draaien na pod restarts?
- Hoe optimaliseer je GPU-scheduling bij concurrerende workloads?
Het onderzoek laat zien: 51% prefereert unified clusters, 29% kiest voor scheiding. De vraag is niet welke aanpak universeel "beter" is. De vraag is: wat past bij jouw organisatie, nu?
De maturiteitscurve: van gescheiden naar unified
Het onderzoek toont een duidelijke maturiteitscurve:
Beginnende fase: gescheiden clusters Teams kiezen voor aparte clusters per workload type. Deze aanpak biedt overzicht en veiligheid, maar verhoogt de operationele overhead:
- Meerdere upgrade-schema's beheren
- Verschillende beveiligingsbeleid handhaven
- Aparte monitoring-setups onderhouden
Volwassen fase: unified clusters met geavanceerde orkestratie Teams draaien één geconsolideerd cluster. Ze beheersen node selectors, taints en tolerations, resource quotas en netwerkbeleid. De operationele overhead daalt significant.
De transitie tussen deze fasen is niet triviaal. Je moet kennis opbouwen van:
- Resource scheduling en prioritering
- Network policies voor workload-isolatie
- Security contexts en pod security standards
- Observability en troubleshooting in multi-tenant omgevingen
Van manueel naar geautomatiseerd: wanneer overstappen?
41% van de organisaties gebruikt dynamische provisioners zoals Karpenter. 27% vertrouwt nog op handmatige orkestratie.
Die 27% heeft een bewuste keuze gemaakt: operationele eenvoud boven tooling-complexiteit. Voor kleinere deployments is dit rationeel.
Maar handmatige processen hebben twee nadelen:
- Ze schalen niet mee met workload-diversiteit
- De operationele kennis blijft impliciet en verdwijnt wanneer teamleden vertrekken
Het kantelpunt? Wanneer de operationele overhead groter wordt dan de leerinvestering voor automatisering. Die afweging maken én de transitie implementeren zonder productieverstoring vraagt echter expertise.
GPU-beschikbaarheid: de onzichtbare beperking
GPU-capaciteit is schaars. Tenzij cloud providers verwachten dat je de volgende OpenAI wordt, moet je strijden om toegang. Specifieke GPU-types zijn vaak simpelweg niet beschikbaar wanneer je ze nodig hebt.
Dit verandert je prioriteiten fundamenteel. Efficiënt gebruik wordt cruciaal: maximale waarde halen uit beschikbare GPUs betekent dat je minder nieuwe capaciteit nodig hebt. Intelligente fallbacks zijn essentieel—automatisch switchen naar alternatieve GPU-types wanneer je voorkeur niet beschikbaar is, zonder workload-onderbreking. Schaalbare architectuur is geen luxe: keuzes die meegroeien met je organisatie en niet tegen je werken bij schaling. Strategische flexibiliteit bepaalt je wendbaarheid: snel kunnen schakelen tussen workloads of providers wanneer de markt verandert.
Dit vraagt meer dan "maak een cluster en draai workloads." Het vraagt strategisch denken over resource-allocatie, workload-prioritering en fallback-scenario's.
Strategisch partnerschap: expertise waar je die nodig hebt
We zien het regelmatig: organisaties die investeren in GPU-infrastructuur maar deze niet effectief benutten. Teams die vastzitten in handmatige node rebuilds terwijl ze moeten focussen op hun core business. Developers die gefrustreerd raken omdat ze GPU-workloads niet effectief kunnen configureren.
Je kunt blijven worstelen met onderbenutte infrastructuur, developers frustreren met tools die ze niet beheersen, en wachten op specifieke GPU-types terwijl de concurrentie doorrent. Of je erkent dat AI-infrastructuur een strategisch probleem is dat vraagt om expertise waar je die mist, en dat je organisatorische capaciteit moet opbouwen parallel aan je infrastructuur.
De technologie is niet de bottleneck. Het gebrek aan strategische planning, operationele volwassenheid en intelligente flexibiliteit is de bottleneck.
Een strategische partner brengt drie kritieke elementen:
1. Objectieve analyse
We starten niet met "je hebt meer hardware nodig." We analyseren:
- Wat is je werkelijke gebruik?
- Welke workloads zijn echt kritiek?
- Welke vaardigheden ontbreken in je team?
- Hoe flexibel is je architectuur tegenover GPU-beschikbaarheid?
- Waar sta je op de maturiteitscurve, en waar wil je naartoe?
2. Pragmatische roadmap
Geen theoretische architectuur voor 5.000 nodes als je er 25 nodig hebt. Geen voortijdige automatisering als je team eerst de basis moet beheersen.
We bouwen een roadmap die past bij je huidige capaciteit en realistische groeidoelen. Dit betekent:
- Architecturen die kunnen schakelen tussen GPU-types
- Workload-prioritering die logisch schaalt
- Automatisering die intelligent omgaat met capaciteitsbeperkingen
- Transitiepaden die je productie niet verstoren
3. Kennisoverdracht
We implementeren niet alleen—we leren je team hoe het werkt. Duurzaam succes betekent dat je uiteindelijk zelfstandig kunt opereren.
We overbruggen de skills gap door hands-on begeleiding te combineren met best practices uit tientallen deployments. Je team leert:
- Hoe je GPU-workloads effectief draait
- Hoe je strategische keuzes maakt die schaalbaar blijven
- Hoe je omgaat met GPU-beschikbaarheidsproblemen
- Hoe je troubleshoot in complexe multi-tenant omgevingen
Van verspilling naar waardecreatie
Bij Krane Labs helpen we organisaties niet om de grootste clusters te bouwen. We helpen ze de juiste clusters te bouwen, op de juiste manier, met teams die weten hoe ze effectief kunnen opereren.
Het gaat niet om hoeveel nodes je kunt schalen. Het gaat om hoeveel waarde je creëert met de resources die je hebt, en hoe snel je aanpast aan een veranderende markt.
Waar staat jouw organisatie op de AI-infrastructure maturiteitscurve? Laten we het gesprek aangaan over hoe we je kunnen helpen de volgende stap te zetten, met een aanpak die past bij je huidige capaciteit en groeidoelen.
Klaar om van verspilling naar waardecreatie te gaan? Laten we het gesprek aangaan over waar jouw organisatie staat op de AI-infrastructure maturiteitscurve, en hoe we je kunnen helpen de volgende stap te zetten.